Meta Unveils AI Swarm That Decodes Hidden 'Tribal Knowledge' in Massive Codebases
Meta Ships AI System That Maps Invisible Code Logic Across 4,100 Files
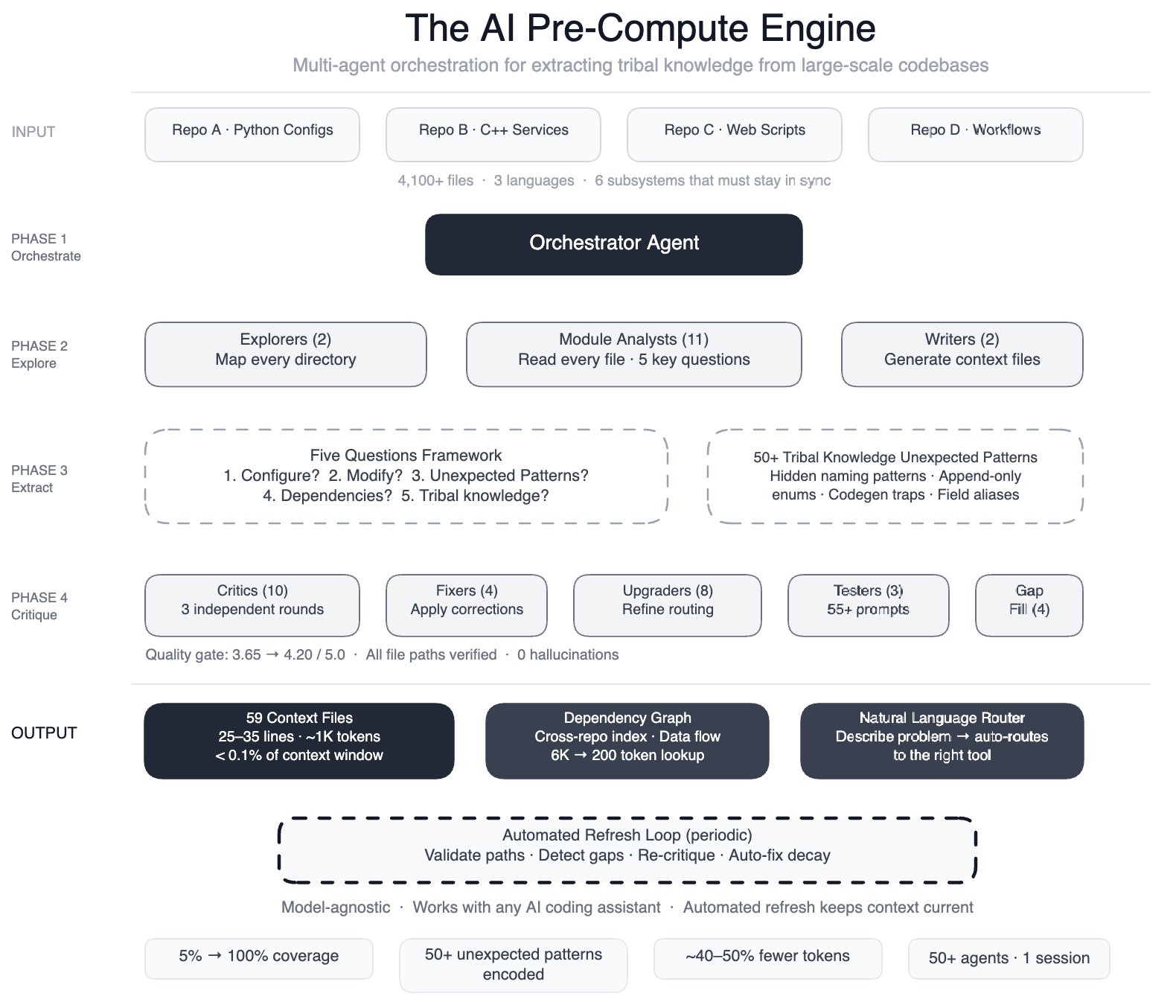
Meta has deployed a swarm of more than 50 specialized AI agents to systematically read and document the so-called ‘tribal knowledge’ buried inside one of its largest data processing pipelines. The system now covers 100% of code modules across four repositories written in Python, C++, and Hack — up from just 5% before the project began.

The result, according to internal tests, is a 40% reduction in the number of tool calls AI agents make when performing development tasks, because they no longer have to guess which file or configuration applies where. The knowledge layer is model-agnostic, meaning it works with leading AI models like GPT-4, Llama, and Claude.
‘The AI Had No Map’ – The Problem Behind the Breakthrough
Meta’s pipeline is a config-as-code system where a single field onboarding touches six subsystems: configuration registries, routing logic, DAG composition, validation rules, C++ code generation, and automation scripts. Engineers previously had to keep all these in sync manually.
“When we tried to use AI agents for development tasks, they fell apart because they had no map of the hidden dependencies,” said a Meta engineer involved in the project. “For example, two configuration modes use different field names for the same operation. Swap them and you get silent wrong output. That kind of knowledge existed only in engineers’ heads.”
Background: The Rise of AI Coding Assistants Without Context
AI coding assistants have become popular, but their effectiveness depends on how well they understand a specific codebase. Meta’s pipeline spans 4 repositories, 3 languages, and over 4,100 files. The company had already built AI systems for operational tasks like scanning dashboards and suggesting mitigations, but extending those to development tasks failed because the AI lacked structured context.
To fix this, Meta built a pre-compute engine: an orchestrated swarm of AI agents that read every file and produced 59 concise context files. These files encode “non-obvious patterns” — design choices and relationships not immediately apparent from the code itself. The system also documents 50+ such patterns that were previously undocumented.
How the AI Swarm Works: From Explorers to Critics
The process involved multiple specialized roles, all coordinated in a single session:
- Two explorer agents mapped the overall codebase structure.
- Eleven module analysts read every file and answered five key questions about its purpose, dependencies, and constraints.
- Two writers generated the context files.
- Ten or more critic passes ran three rounds of independent quality review.
- Four fixers applied corrections found by critics.
- Eight upgraders refined the routing layer between agents.
- Three prompt testers validated 55+ queries across five user personas.
- Four gap-fillers ensured remaining directories were covered.
- Three final critics ran integration tests on the complete output.
The entire pipeline — more than 50 specialized tasks — runs automatically and is self-maintaining. Every few weeks, automated jobs validate file paths, detect coverage gaps, re-run quality critics, and auto-fix stale references. “The AI isn’t just a consumer of this infrastructure; it’s the engine that runs it,” the engineer added.
What This Means for Enterprise AI Coding Assistants
The approach demonstrates that enterprise-scale AI code assistants need structured domain knowledge, not just a large context window. By pre-computing tribal knowledge into model-agnostic files, Meta has created a system where AI agents can navigate complex, multi-repo codebases with minimal trial and error.
For other organizations, the key takeaway is that manual documentation of all business rules is impractical. Instead, AI can be used to extract and maintain that knowledge automatically. The 40% reduction in tool calls translates directly into faster, more reliable code edits — a critical advantage for companies dealing with equally intricate pipelines in finance, healthcare, or logistics.
Meta plans to open-source the concept, though no timeline has been announced. The company is also exploring how the same technique could be applied to code reviews, security audits, and compliance checks.