Meta's Adaptive Ranking Model: Revolutionizing Ad Inference with LLM-Scale Efficiency
Meta has developed the Adaptive Ranking Model to overcome the challenges of scaling ads recommendation systems to LLM-level complexity. This innovative approach tackles the "inference trilemma"—the difficulty of balancing model size, latency, and cost—by dynamically matching model complexity to user context. Below, we explore how this works, the key innovations, and the real-world impact on advertisers.
- What is the inference trilemma in ad recommendation systems?
- How does the Adaptive Ranking Model bend the inference scaling curve?
- What are the three key innovations behind this model?
- How does the model serve LLM-scale models at sub-second latency?
- What are the business results for advertisers?
- How does the model ensure cost efficiency at global scale?
- What does the future hold for this technology?
What is the inference trilemma in ad recommendation systems?
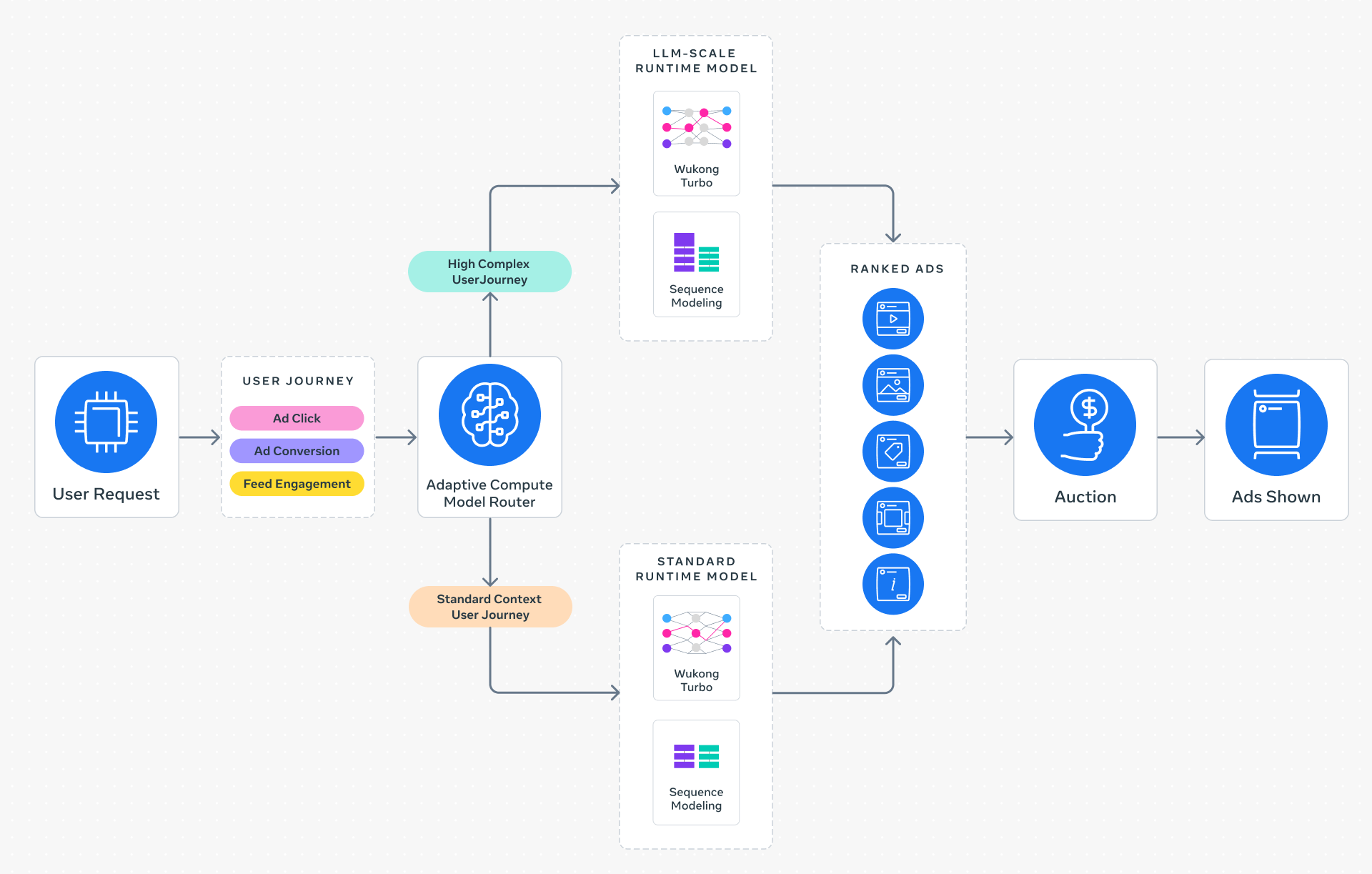
As Meta scales its ad recommender models to LLM size and complexity, it faces a fundamental trade-off known as the inference trilemma. This trilemma involves balancing three competing demands: model complexity (needed for deep understanding of user intent), low latency (sub-second responses for real-time ads), and cost efficiency (serving billions of users without exorbitant infrastructure costs). Traditional "one-size-fits-all" inference approaches force a compromise—either use a smaller model (sacrificing accuracy) or accept higher latency/cost. The Adaptive Ranking Model breaks this deadlock by dynamically selecting the optimal model for each request, aligning compute resources with the specific context of the user.

How does the Adaptive Ranking Model bend the inference scaling curve?
Instead of applying the same large model to every query, the Adaptive Ranking Model intelligently routes requests based on a rich understanding of a person's context and intent. It replaces a static inference pipeline with a dynamic system that adjusts model complexity per request. For simple user intents, a lightweight model handles the task quickly; for nuanced or high-value interactions, a full-scale LLM provides deeper analysis. This "bending" of the scaling curve means that the overall system maintains sub-second latency and cost efficiency, while still benefiting from LLM-scale intelligence where it matters most. The result is a high-ROI approach that scales inference capacity without proportional increases in resource consumption.
What are the three key innovations behind this model?
The Adaptive Ranking Model is built on three foundational innovations:
- Inference-Efficient Model Scaling: A request-centric architecture that serves an LLM-scale model at sub-second latency, enabling sophisticated understanding of user interests without performance degradation.
- Model/System Co-Design: Hardware-aware model architectures that align with the capabilities and limitations of underlying silicon (e.g., GPUs, TPUs), improving utilization in heterogeneous environments.
- Reimagined Serving Infrastructure: Leveraging multi-card architectures and hardware-specific optimizations to enable O(1T) parameter scaling—serving trillion-parameter models with unprecedented efficiency.
Together, these innovations allow Meta to deploy LLM-scale models in real-time ads while keeping operational costs manageable.
How does the model serve LLM-scale models at sub-second latency?
Achieving sub-second latency with models of 1 trillion parameters requires a fundamental rethink of the inference stack. The Adaptive Ranking Model uses request-centric scheduling to activate only the necessary parts of the network for each query. Combined with model/system co-design, it optimizes data movement and computation across multiple GPUs or specialized accelerators. The serving infrastructure also employs hardware-specific kernels and memory management to minimize bottlenecks. As a result, even when the full model is enormous, the effective computational load per request remains low enough to meet the strict latency requirements of real-time ad delivery—often under 100 milliseconds.
What are the business results for advertisers?
Since launching on Instagram in Q4 2025, the Adaptive Ranking Model has delivered measurable gains. For targeted users, advertisers have seen a +3% increase in ad conversions and a +5% increase in ad click-through rate. These improvements come without additional computational costs, thanks to the model's efficiency. By better understanding user intent, the system surfaces more relevant ads, leading to higher engagement and better return on ad spend. This is particularly beneficial for businesses of all sizes, as the incremental gains compound across millions of daily ad impressions.
How does the model ensure cost efficiency at global scale?
Cost efficiency is achieved through dynamic resource allocation. The Adaptive Ranking Model avoids wasting compute on easy requests by using lightweight models for them, reserving heavy LLM inference only for challenging cases. Additionally, the hardware-aware design maximizes utilization of existing infrastructure—reducing the need for additional server deployments. The reimagined serving infrastructure also supports efficient multi-card scaling, meaning Meta can serve billions of users without linearly increasing hardware costs. This is a stark contrast to traditional approaches, where scaling model size would proportionally inflate operational expenses.
What does the future hold for this technology?
The Adaptive Ranking Model opens the door to further integration of LLM-scale intelligence across Meta's entire ads stack. Future iterations may extend the dynamic routing to include even larger models (e.g., multi-modal LLMs) and more granular user contexts. This could lead to personalized ad experiences that adapt in real-time to user behavior. Additionally, the underlying techniques (request-centric inference, co-design) are applicable beyond ads—they could transform other real-time AI services like news feed ranking or virtual assistants. Meta is positioning itself to continue leading in scalable, efficient AI for global applications.