KAME: Bridging the Speed-Knowledge Gap in Conversational AI
Conversational AI faces a classic trade-off: systems can either respond instantly with shallow answers or deliver deep knowledge after a noticeable delay. Sakana AI's new architecture, KAME (Knowledge-Access Model Extension), shatters this binary by combining the real-time responsiveness of a direct speech-to-speech (S2S) model with the rich reasoning of a large language model (LLM). Below, we explore how KAME works and why it matters.
1. What is the fundamental challenge in conversational AI?
The central tension lies between response speed and response quality. Direct S2S models can start speaking almost instantly, often before the user finishes asking a question, but they lack deep factual knowledge. Cascaded systems, which convert speech to text, process it through an LLM, and then synthesize speech, deliver much smarter answers but introduce ~2.1 seconds of latency—enough to break the natural rhythm of conversation. KAME was designed to overcome this either-or choice by using a tandem approach that doesn't force developers to sacrifice one for the other.
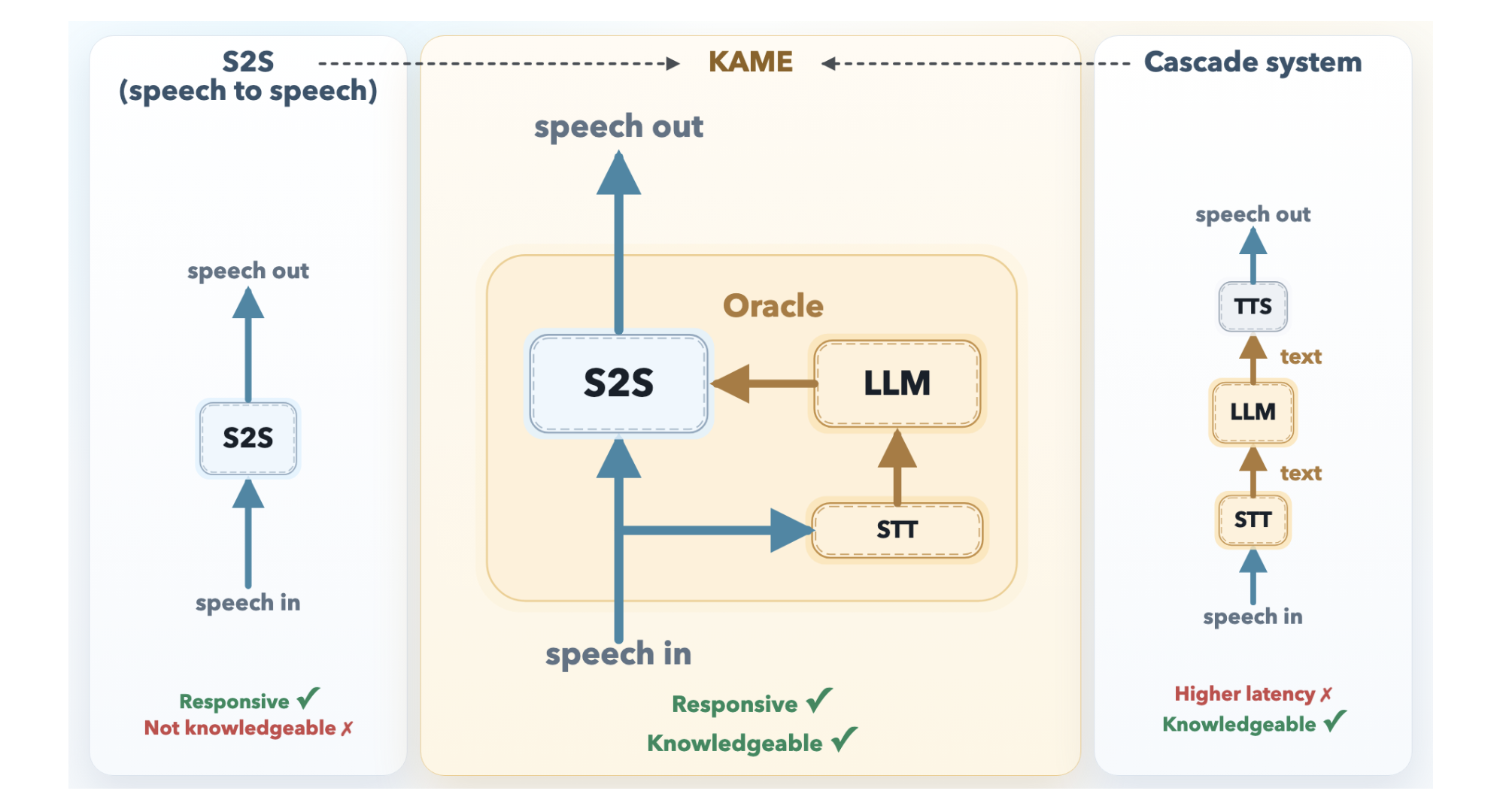
2. How do direct S2S models work and what are their limitations?
Direct S2S models, such as KyutAI's Moshi, are monolithic transformers that process audio tokens in a continuous loop. They take in raw audio and directly output audio, all within a single network. This architecture allows extremely low latency—in many cases, the model begins responding before the user's sentence ends. However, because audio signals carry far more information than text (tone, emotion, rhythm), the model must dedicate significant capacity to modeling these paralinguistic features. Consequently, it has less room left for factual knowledge and complex reasoning, resulting in answers that can be shallow or vague compared to text-based LLMs.
3. What are the drawbacks of cascaded S2S systems?
Cascaded systems route user speech through three separate components: an Automatic Speech Recognition (ASR) model, a large language model (LLM), and a Text-to-Speech (TTS) engine. The ASR converts audio to text; the LLM generates a text response; and the TTS synthesizes that response back into speech. While this pipeline allows plugging in any frontier LLM—ensuring excellent knowledge quality—it suffers from a major latency penalty. The system must wait for the user to finish speaking before ASR and LLM processing can begin. The result is a median delay of about 2.1 seconds, which noticeably interrupts the flow of natural conversation and makes interactions feel robotic.
4. How does KAME's tandem architecture solve both problems?
KAME operates as a tandem system with two asynchronous components running in parallel. The front-end is a direct S2S module based on Moshi, which processes audio in real-time (every ~80 milliseconds) and begins generating spoken responses immediately—preserving near-zero latency. The back-end consists of a streaming speech-to-text (STT) component paired with a full-scale LLM. As the user speaks, the STT continuously builds a partial transcript and periodically feeds it to the LLM, which generates candidate text responses called oracles. These oracles are injected into the front-end's output stream without waiting for the user to finish, effectively letting the system "think while speaking."
5. What is the oracle stream in KAME?
The oracle stream is the key innovation that extends Moshi's original three-stream design (input audio, inner monologue in text, and output audio) with a fourth stream. This stream carries the candidate responses generated by the back-end LLM. Because the front-end S2S module and back-end LLM operate asynchronously, the oracle stream provides a running buffer of smarter, more knowledgeable text suggestions that can be injected into the output audio stream at any time. The front-end uses these oracles to enrich its immediate responses, ensuring the final speech benefits from deep reasoning without incurring the full latency of a cascaded pipeline.
6. How does KAME maintain low latency while injecting LLM knowledge?
KAME achieves low latency by never blocking the front-end's audio output. The front-end starts speaking immediately using its direct S2S capability. Meanwhile, the back-end LLM processes partial transcripts as they arrive and emits oracles incrementally. These oracles are injected into the front-end's output stream asynchronously, much like a live teleprompter. The front-end can adjust its spoken content mid-sentence based on the latest oracle, blending the real-time flow of direct S2S with the knowledge depth of the LLM. This approach keeps the median response latency at or below 200 milliseconds—dramatically lower than the 2-second delay of cascaded systems—while still delivering factually rich and coherent answers.